
Now Reading: New Computational Biology Tool Automates And Standardizes Genome Sequencing Analysis
-
01
New Computational Biology Tool Automates And Standardizes Genome Sequencing Analysis

New Computational Biology Tool Automates And Standardizes Genome Sequencing Analysis
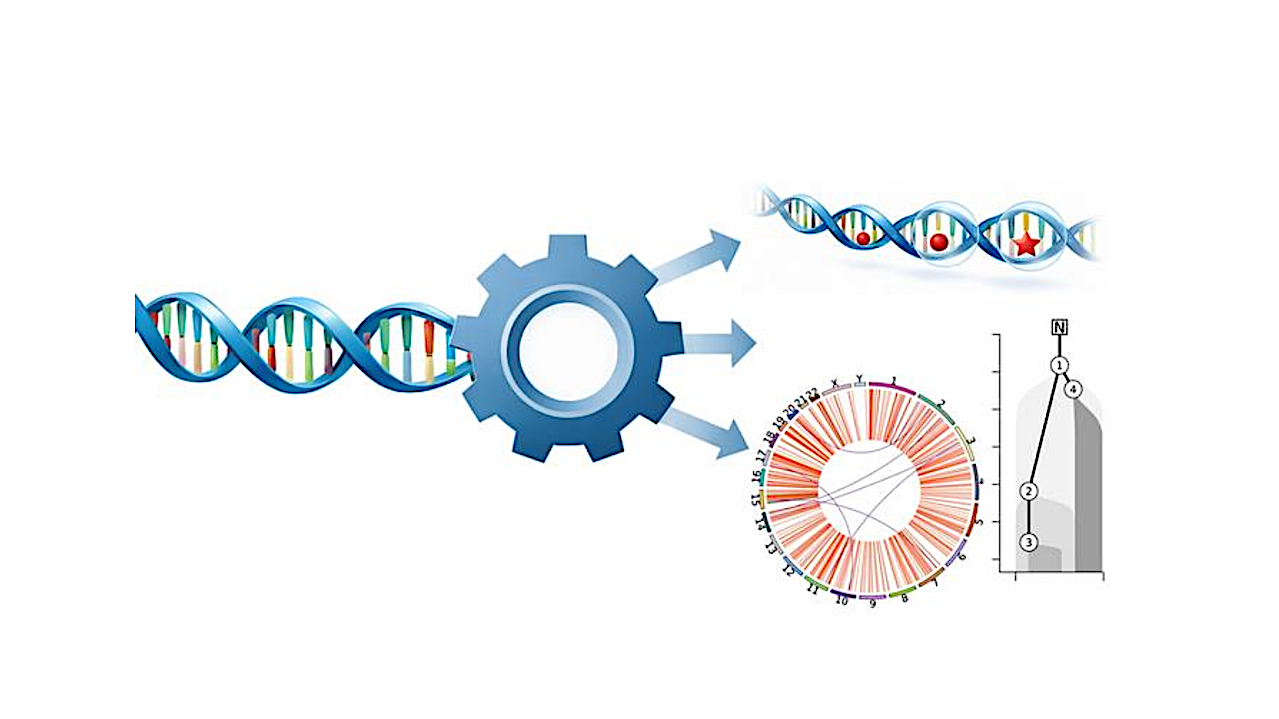
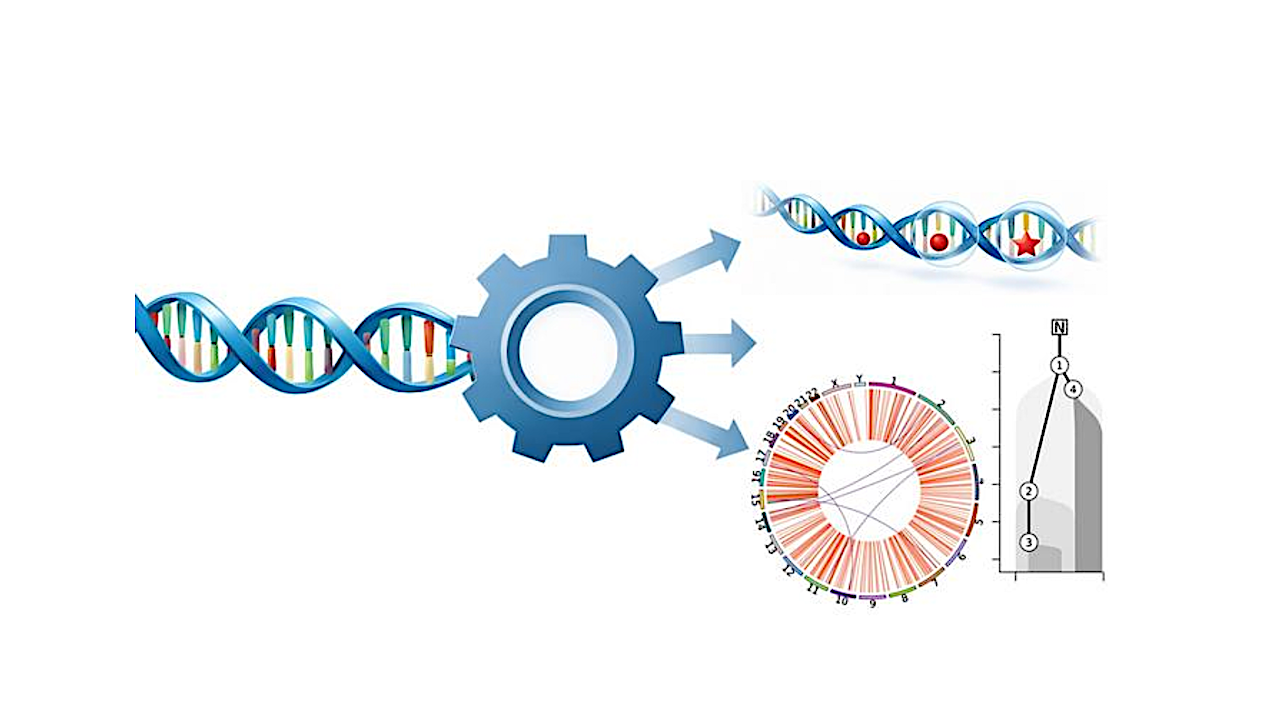
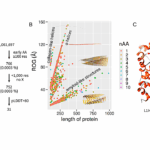
This illustration demonstrates how metapipeline-DNA processes raw genome sequencing data. It begins by aligning the sequence of DNA base pairs to a reference genome. Then produces sets of detected variants and other genetic and evolutionary features. Credit Yash Patel, Sanford Burnham Prebys
Editor’s note: with recent speculation about the potential habitability of other worlds and understanding the processes whereby other biospheres arise and evolve, thought needs to be given to developing sensor technology to do in situ analysis of samples collected by robotic systems and human crews. With size and power and energy constraints in mind, having the most compact way to quickly analyze a sample or monitor alien life forms will be of great utility to future astrobiology expeditions. Systems such as the one described below are good step in this direction.
In a single experiment, scientists can decipher the entire genomes of many patient samples, animal models or cultured cells. To fully realize the potential to study biology at this unprecedented scale, researchers must be equipped to analyze the titanic troves of data generated by these new methods.
Scientists at Sanford Burnham Prebys Medical Discovery Institute and the University of California Los Angeles published findings March 17, 2026, in Cell Reports Methods discussing building and testing a new computational tool for tackling massive and complex sequencing datasets. The new resource, named metapipeline-DNA, may also make sequencing data analysis more standardized across different research labs.
The sequence of a single human genome represents about 100 gigabytes of raw data, the rough equivalent of 20,000 smartphone photos. The sheer scale of experimental data increases significantly as tens or hundreds of genomes are added into the mix.
As the technology to produce this data has rapidly advanced over the last 10-15 years and become more affordable and accessible, many labs have built their own software to use for analysis, or customized open-access tools shared freely by colleagues. Some of these resources only work on specific supercomputing or cloud computing systems.
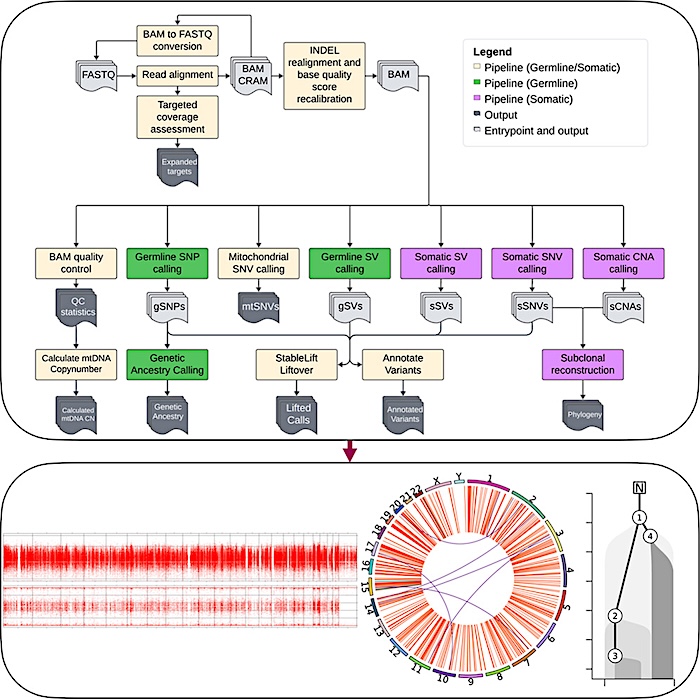
Graphical Abstract — CELL
This fragmented software landscape can complicate collaboration across institutions, add difficulties when labs move to new institutions or institutions switch to new computing solutions, and contribute to a lack of standardization as well as challenges reproducing studies with different tools.
“Bioinformatics pipelines for genomic sequencing data such as metapipeline-DNA are designed to standardize analysis of all this data to make sure it is processed in a uniform way, and in a reproducible way,” said Yash Patel, MSc, a cloud and AI infrastructure architect at Sanford Burnham Prebys and co-first author of the study.
“The goal is to automate quality control, determination of genetic variants and all the other analysis steps to make it much easier so that researchers do not need to write their own code to process their data.”
The metapipeline-DNA development team emphasized the software’s ability to detect and recover from common errors. Even with the powerful supercomputing clusters scientists use to analyze sequencing data, failed runs can cost days of computing time and delay new discoveries.
“In designing the software, we focused on making sure that the choices we present to the users are fully validated before the pipeline runs,” said Paul Boutros, PhD, MBA, director and professor in the NCI-Designated Cancer Center at Sanford Burnham Prebys and senior vice president of Data Sciences.
“In our lab, we don’t want to suffer a setback due to a preventable configuration error, and we don’t want it to happen to anyone using our pipelines.”
The collaborative development process has included 43 contributors making 1,408 pull requests to enhance the underlying code, and 46 individuals submitting 1,124 suggestions, requests for features and/or reports of issues.
To improve the ability of metapipeline-DNA to determine where changes in the genome have occurred, the scientists worked with the Genome in a Bottle Consortium led by the U.S. Department of Commerce’s National Institute of Standards and Technology. By incorporating this public-private-academic consortium’s meticulously validated resources, the researchers reduced the rate of false positives without reducing the tool’s precision in finding true genetic variants.
The researchers also produced two case studies demonstrating the pipeline’s capabilities for cancer research. The investigators used metapipeline-DNA to analyze sequencing data from five patients that donated both normal tissue and tumor samples to the Pan-Cancer Analysis of Whole Genomes dataset, as well as another five from The Cancer Genome Atlas.
The next step is to get metapipeline-DNA into more labs to accelerate discoveries, and to continue improving the resource with more user feedback.
“This tool should enable labs to process data without needing a lot of background in computation or computer infrastructure, and without having to optimize for their specific computing environment,” said Patel.
In addition, the authors plan to build upon this foundation to create automated, end-to-end solutions for analyzing sequencing of other biological molecules such as RNA and proteins.
“Workflows across different biomolecules can share the architecture, automation and quality control methods of metapipeline-DNA such that improvements to any single pipeline can improve the others,” said Boutros, the senior and corresponding author of the manuscript.
“We’re excited to expand to other data-intensive high-throughput sequencing techniques to continue improving the pace and efficiency of discovery in our lab, at Sanford Burnham Prebys and throughout the research community.”
metapipeline-DNA: A Comprehensive Germline & Somatic Genomics Nextflow Pipeline, Cell Reports Methods (open access)
Rapid improvements in DNA sequencing technologies have expanded the breadth of genomic features, ranging from nuclear, mitochondrial, and evolutionary variation in germline and somatic contexts, which can be elucidated from sequencing data. In parallel, analytical workflows required to process and identify these features have become increasingly complex, relying on specialized tools and algorithms with varying assumptions and computational requirements. Comprehensive analysis, therefore, requires significant integration effort, limiting scalability, reproducibility, and consistent quality controls. To address this need for a flexible, robust framework that accommodates diverse sequencing methods and feature classes while being highly scalable and adaptable across computational environments, we created metapipeline-DNA to automate genomic analyses.
Astrobiology, genomics,










Related Posts


Stay Informed With the Latest & Most Important News
Previous Post
Next Post





Advertisement
-
 01Two Black Holes Observed Circling Each Other for the First Time
01Two Black Holes Observed Circling Each Other for the First Time -
 02From Polymerization-Enabled Folding and Assembly to Chemical Evolution: Key Processes for Emergence of Functional Polymers in the Origin of Life
02From Polymerization-Enabled Folding and Assembly to Chemical Evolution: Key Processes for Emergence of Functional Polymers in the Origin of Life -
 03Astronomy 101: From the Sun and Moon to Wormholes and Warp Drive, Key Theories, Discoveries, and Facts about the Universe (The Adams 101 Series)
03Astronomy 101: From the Sun and Moon to Wormholes and Warp Drive, Key Theories, Discoveries, and Facts about the Universe (The Adams 101 Series) -
 04True Anomaly hires former York Space executive as chief operating officer
04True Anomaly hires former York Space executive as chief operating officer -
 05Φsat-2 begins science phase for AI Earth images
05Φsat-2 begins science phase for AI Earth images -
 06Hurricane forecasters are losing 3 key satellites ahead of peak storm season − a meteorologist explains why it matters
06Hurricane forecasters are losing 3 key satellites ahead of peak storm season − a meteorologist explains why it matters -
 07Binary star systems are complex astronomical objects − a new AI approach could pin down their properties quickly
07Binary star systems are complex astronomical objects − a new AI approach could pin down their properties quickly